Week4:本周主要针对上周学习的RISC处理器的硬件组成,根据分析处理器性能评估公式,学习一些提高处理器的性能的方法,如流水线、定制化数据通路、超标量、乱序发射等。
内容回顾
到目前为止,我们学习了一个基本RISC处理器的硬件组成,该硬件架构也称为单周期的处理器架构。单周期的处理器是在一个周期内完成取指令、指令解码、MAC计算、访问数据、写回数据这些步骤,那么有什么办法可以进一步提高处理器的速度呢?首先,我们来看一下前几周介绍的一个经典的评估指令集执行效率(处理器性能)的公式:
$$\frac{Time}{Program}={\frac{Instructions}{Program}}\times{\frac{Clock\ cycles}{Instruction}}\times{\frac{Time}{Clock\ cycles}}\tag{1}$$
该公式的左端是程序执行的时间,可以反映处理器的性能。右端通过公式的巧妙拆分,变成了一个由程序包含的指令数量、每条指令执行的时钟周期数、每个周期需要的时间三部分组成的乘积式。对于人工智能芯片而言,一般往往用吞吐率(Throughput)来衡量AI芯片的性能,吞吐率的公式就是将上述公式1的分子分母进行互换,并将程序的内容换算成乘加操作(MAC)。转换后的公式如下:
$$Throughput=\frac{Operations}{Time}={\frac{MAC}{Instructions}}\times{\frac{Instruction}{Clock\ cycles}}\times{\frac{Clock\ cycles}{Time}}\tag{2}$$
从等式的右端可以看出,由三部分组成,分别是每条指令包含的MAC数(MAC指令密度)、每个周期执行的指令数(一般认为“1”,因为每个周期读取一条指令)、每秒执行的周期数(主频)。对于AI计算而言,程序的内容主体为MAC指令,如果没有MAC指令,则完成一次乘累加运算需要两个指令,因此把一条MAC指令即一个乘法和一个加法操作等效为2次操作。
因此,吞吐率的公式可以简化为
$$Throughput\ (MOPS)={MAC\ Utilizatoin}\times{\ 1 \ }\times{f\ (MHz)}\tag{3}$$
例如,对于之前提到的 Load Load MAC 指令,其MAC Utilization为 $\frac{1}{3}$ ,假设 $f$ 为100MHz,一个MAC等效为2次操作,则该处理器的吞吐率约为66.67MOPS。基于以上分析和基础,下面我们将通过分析吞吐率公式的组成优化处理器的硬件架构。
流水线技术
基本概念
流水线(Pipeline)技术是指程序在执行时候多条指令重叠进行操作的一种准并行处理实现技术。通过在硬件架构中插入寄存器来切分各个执行阶段(取指令、指令解码、MAC计算、访问数据、写回数据),如图1所示: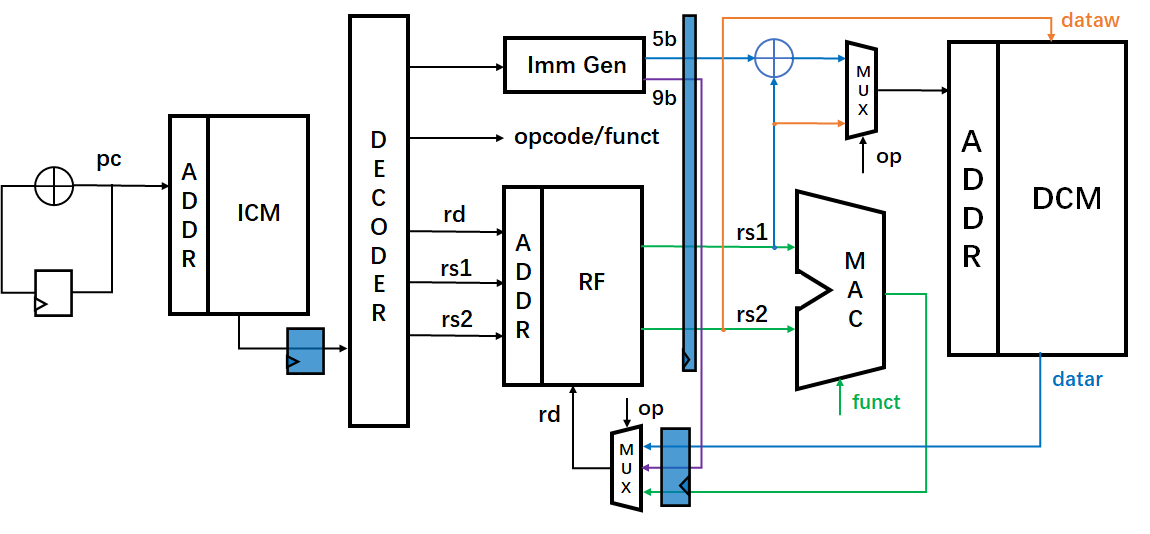
对于采用流水线架构的处理器而言,其单条指令的执行时间几乎没有发生变化,依旧需要完成取指令、指令解码、MAC计算等步骤。但由于插入寄存器后每个步骤执行的时间变得很短,故处理器的主频可以得到很大的提升,假设每一个步骤运行的时间相等,那么采用5段流水线的频率可以提高5倍。当执行多条指令时,并行计算的优势便体现出来,通过随着源源不断地取指令,几乎每个CLK便可以完成一条指令。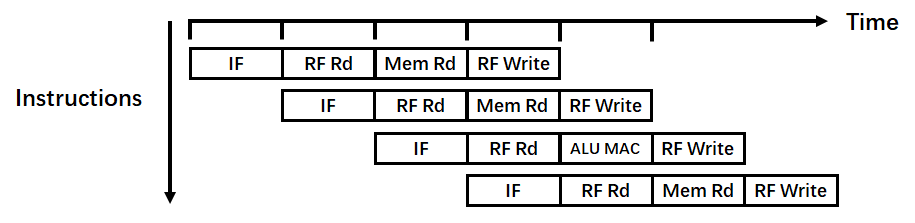
同时,通过吞吐率的公式分析可知,采用流水线的技术实际上很大程度提高了处理器的频率,因此处理器的性能也会随着主频的提高呈同倍率的提升。
冒险现象(Hazard)
然而,流水线技术并不是十分完美的,在指令并行执行的过程中,会产生一些“冒险”现象,如数据冒险(Data Hazard)、结构冒险(Structure Hazard)以及控制冒险(Control Hazard)等,带来各种硬件资源冲突,数据的读写顺序等问题。
- 结构冒险:所需的硬件正在为之前的指令工作;
- 数据冒险:需要等待之前的指令完成数据写入;
- 控制冒险:需要根据之前的指令决定接下来的行为;
这里以数据冒险为例,在上述案例中的计算指令中,指令的组成为Load、Load、MAC,那么其指令流水线的示意图如图3所示。
因此,对于Load、Load、MAC指令而言,在没有等到数据准备好时便执行MAC操作,其结果必然会出现错误。为了解决这个问题,最简单的方法便是在指令中插入空泡指令(Bubble),即一个空指令,为后续指令执行所需的数据争取一定的时间。其空指令插入示意图如图4所示: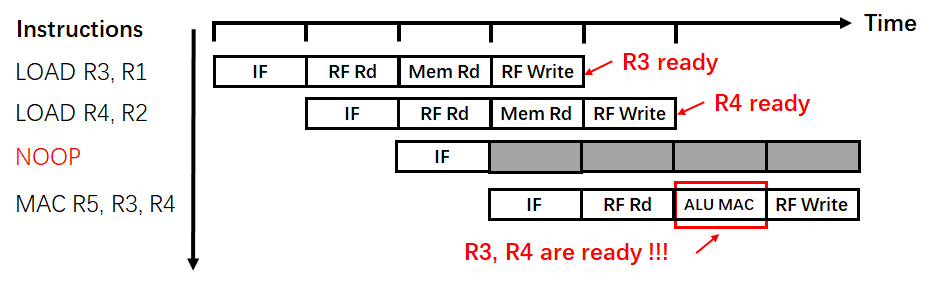
可以看出,空指令的插入在一定程度上解决了数据冒险的问题,但他也导致了处理器的性能的损失,如原先的MAC Utilization为 $\frac{1}{3}$ 现在变成了 $\frac{1}{4}$, 吞吐率降低了25%。同时,我们也发现了流水线技术的使用,一方面给处理器性能带来了很大地提升,但另一方面也造成不少的麻烦和困扰,如下面两点:
- 1、处理器性能的损失,同时,对于流水线级数较深的处理器而言,流水线越深,其MAC Utilization的比例会降低地更加严重,使得处理器性能反而得不到很大地提升。
- 2、对于Branch/Jump等分支跳转指令而言,由于指令存在着不确定性,对处理器性能有一定的损失。以Branch指令为例,如果两个数相比较不满足条件,则需要跳转到其他指令,那么原先一大堆已获取的指令将全部抛弃重来,一定程度上造成了指令的浪费。
定制化流水线
Forwarding
对于上述由于data hazard造成MAC Untilization 大幅降低的问题,其实是有办法解决的,那就是采用定制化的流水线来改进原先的硬件结构。
如图5所示,由于寄存器R3和R4的值在Cycle3和Cycle4便可以得到,因此我们可以提前将寄存器R3和R4的值直接连接到ALU中的计算单元,同时保持原先的数据通路,在Cycle4和Cycle5依旧写回到Regs File当中。在经典的计算机体系结构中,这种方法也叫做”forwarding”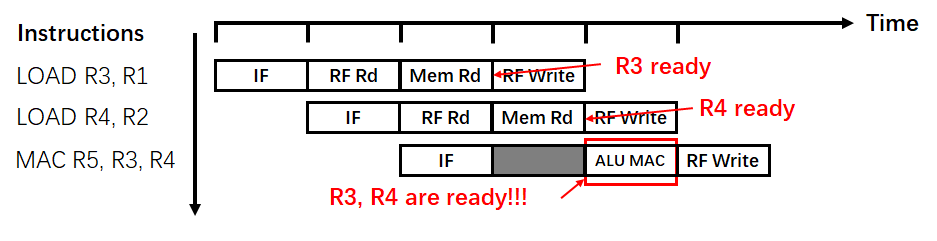
那么,在实际处理器中,我们该如何去实现这种硬件结构呢?对于某一段程序,我们在优化硬件电路时,最主要的是优化程序中最频繁出现的程序块,在本节讨论的范围中就是Load、Load、MAC指令,因此对于这部分优化,我们可以采用移位寄存器的方式,来提前保存从Regs File中读取的R3和R4,具体硬件电路如图6所示。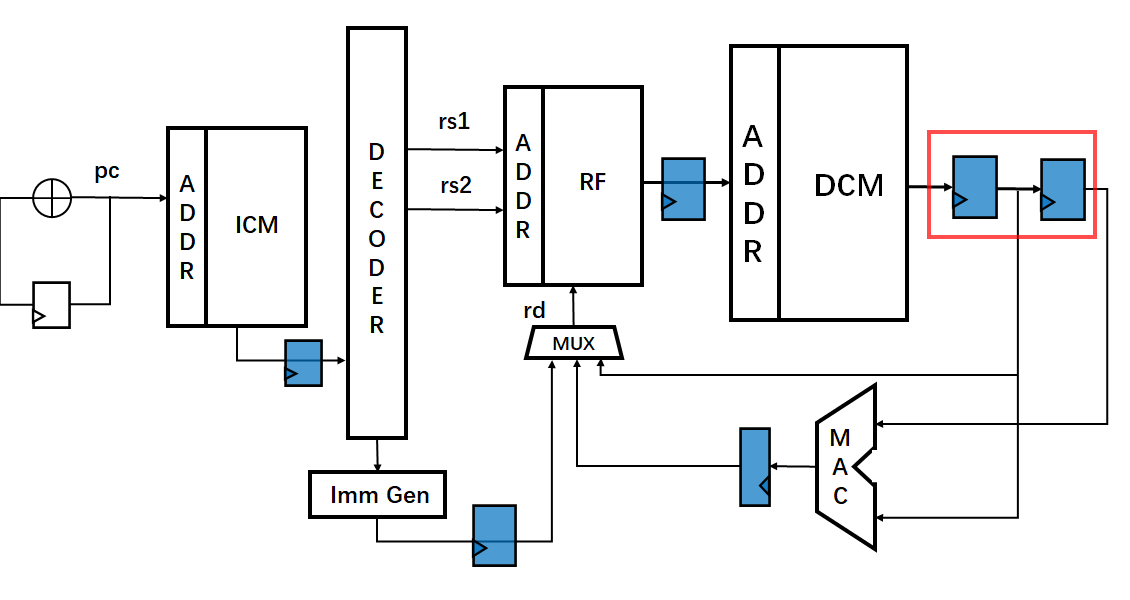
Aggressive Target
到目前为止,我们用定制化的流水线解决了data hazard的问题,其MAC Utilization已经变到了原先的 $\frac{1}{3}$,那么我们还能进一步提高MAC Utilization吗?答案当然是可以的。如图7所示,我们可以将指令集稍作修改,将第二条Load指令与MAC指令进行合并,作为一条新的指令Load-MAC,那么再Load之后的数据直接与上一次Load的数据进行运算,计算完成后再写回Regs File,那么此时MAC Utilization就变成了 $\frac{1}{2}$。那么如果有Load-Load-MAC指令的话,其MAC Utilization就变成了 $100%$。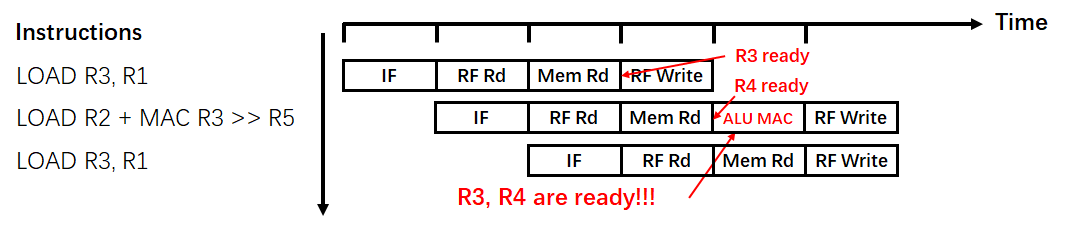
此时,当Load MAC指令合并后,也引起了一个思考?因为第2周学习的有关RISC和CISC的区别时,一个重要的区分标准时ALU是否直接对存储器进行访问,那么当Load MAC变成一条指令后,此时的处理器是否还是RISC处理器?其实这两者都有自己的解释方式。
- 对于CISC而言,是把Load-MAC指令看作是一条MAC指令,那么此时MAC指令不再需要进行Load指令取数再进行MAC操作,也就是说通过MAC指令直接可以对存储器进行访问,因此相当于是CISC处理器的操作。
- 作为RISC而言,虽然Load-MAC指令是一条指令,但实际ALUM所需要的数据依旧是通过与Load指令相同的操作获取,这本质上和先Load指令再MAC指令没有区别,因此仍就是RISC处理器。
所谓的CISC也好,RISC也好,无非是站在不同角度来解释,因此是各有各的道理(我本人更加倾向于RISC的解释^-^),我们只要理解其数据存取的本质就行。
超标量处理器
现在,我们再来看一下吞吐率的公式
$$Throughput\ (MOPS)={MAC \ Utilizatoin}\times{\ 1 \ }\times{f\ (MHz)}$$
与最原始的处理器吞吐率相比,通过定制化流水线后,MAC Utilization已经变为了 $\frac{1}{2}$, $f$已经变为了原来的4倍,假设 $f$ 为100MHz,那么现在的吞吐率就变为了400MOPS。那么本节我们来看一下另一种优化吞吐率的方法。
超标量处理器的概念
- 标量处理器:每个周期执行一条指令的处理器
- 超标量处理器:每个周期执行多条指令的处理器,同时执行的多条指令使用的是不同硬件单元
因此,对于超标量处理器而言,如果多条指令之间存在着数据依赖关系,或者使用的是同一个硬件单元,那么就无法使用超标量技术。
超标量流水线(Superscalar Pipeline)
以Load-MAC指令为例,使用超标量流水线架构在一个时钟周期内会执行多条指令,如图8所示。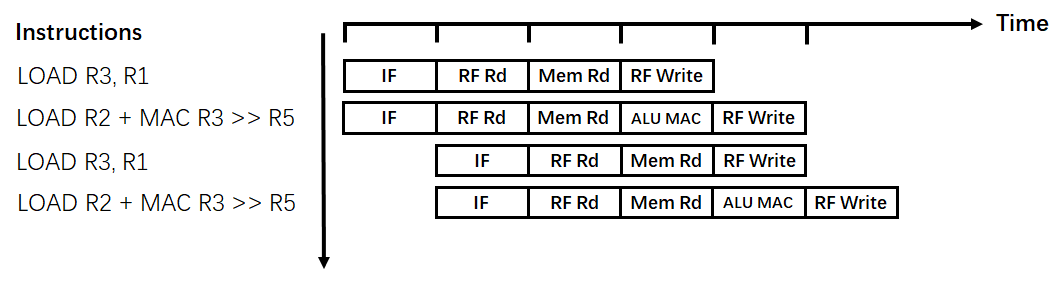
那么相比于原先的流水线架构而言,每个周期执行指令数为“2”,则处理器的吞吐量为
$$Throughput\ (MOPS)=2\times{\frac{1}{2}}\times{\ 2 \ }\times{400\ (MHz)}=800MOPS$$
在具体的硬件结构实现中,由于两条指令均需要对Memory进行访问,因此在硬件架构中需要使用两个Memory单元,以满足需求。具体结构图如图9所示。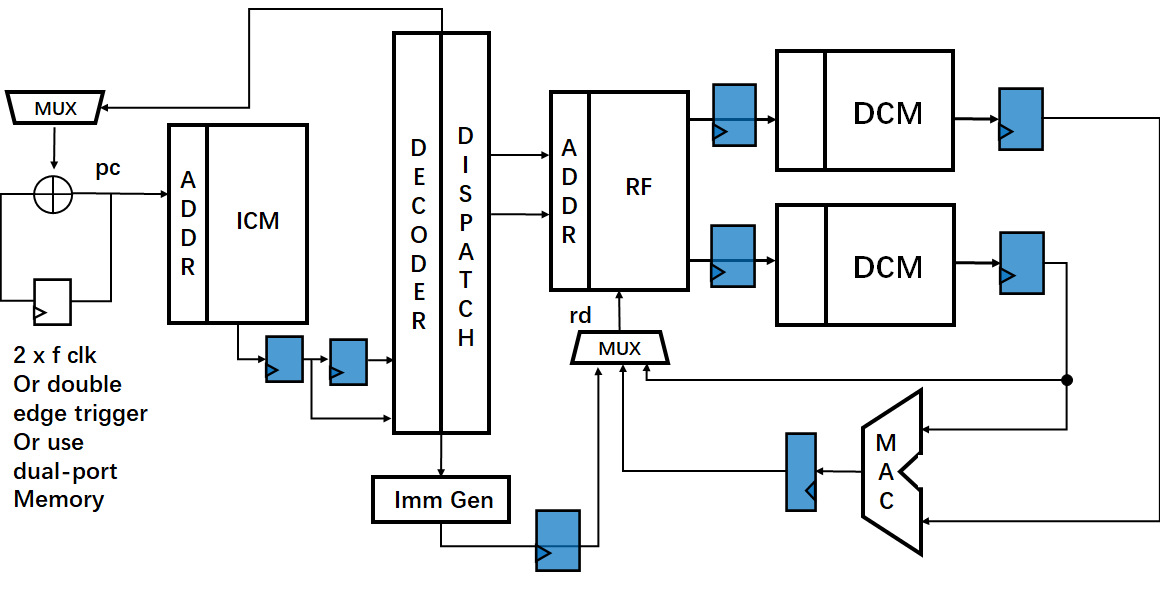
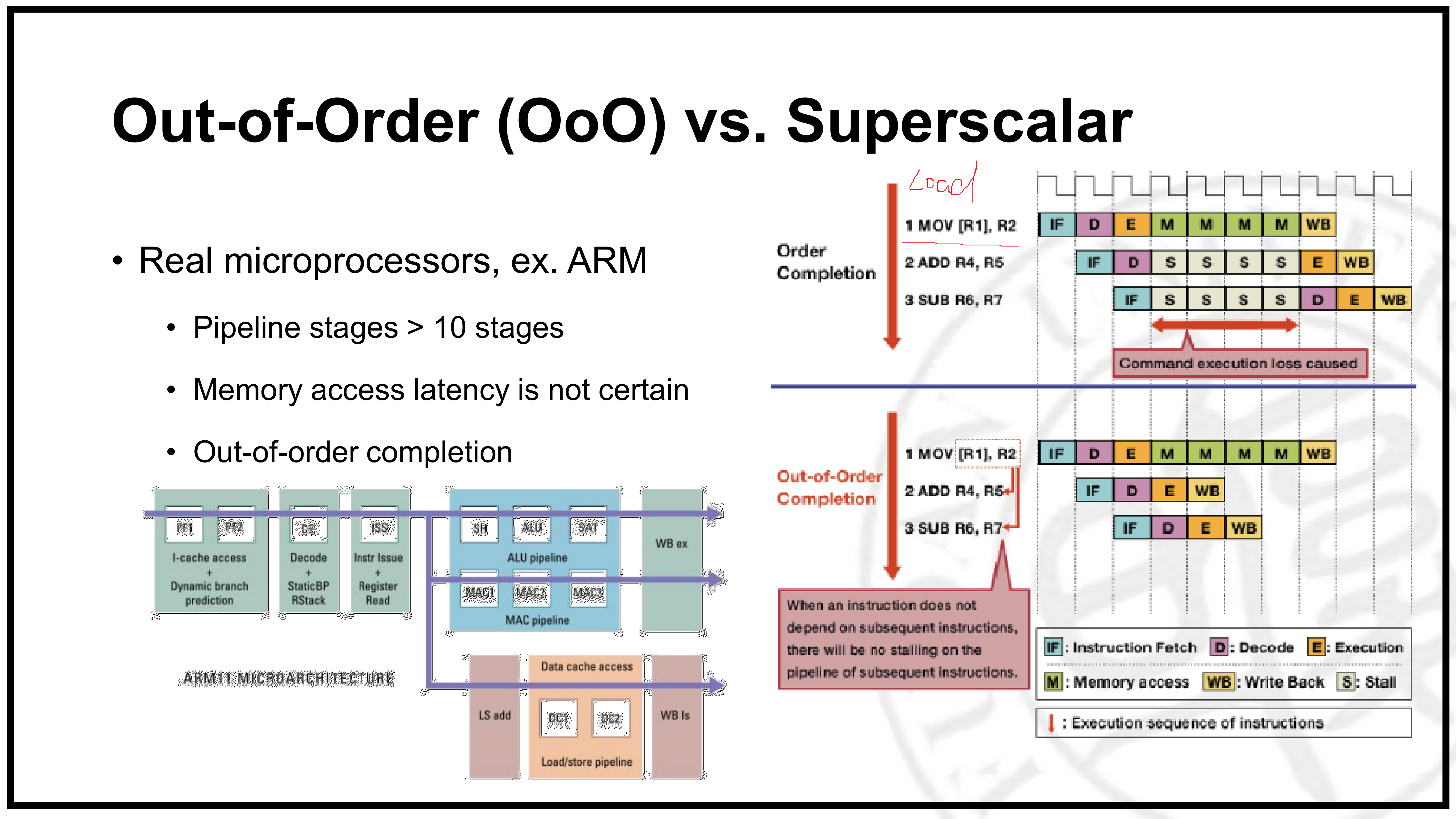
乱序发射(OoO)
由于之前的指令都是顺序执行的,因此指令间并行时产生冒险现象时,后面的指令就需要等待。如果采用乱序发射技术,即将后面没有相关性的指令先执行,就可以尽可能地提高硬件利用率,因此它能够提高处理器执行指令的效率。
乱序发射(Out of Order)是指CPU采用了允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。
当然,乱序发射也可以解决其它问题,如:在现代高性能的处理器中,流水线级很长,由于存在L1、L2 catche,导致对Memory的访问是不确定的,这就导致了如Load指令与其他指令执行的时间会不一致,对Memory的访问时间有可能需要好几个周期。通过乱序发射技术,可以将处于空闲状态的指令提前执行,如下图10所示。这样提高了硬件的利用率,也就提高了指令的执行效率。