该项目是我的本科毕业设计,主要设计了一种卷积神经网络(用于手写数字识别)推理的硬件加速器,使用 16 位定点数对网络参数进行量化,实验基于ZYNQ(XC7Z010)硬件平台,完成了加速器的实现与测试,最终使用 MNIST 测试集的准确率为 98.42%,与Tensorflow 32 位浮点数计算结果仅相差 0.05%;与CPU(i5-6200U)推理速度相比,单张图片推理加速比达到了84.8倍,10000 张图片推理加速比达到了43.6倍。
项目回顾
项目大纲
首先是整个项目的总体回顾,整体工作的内容大纲如下:
实验平台搭建
最终的实验平台是基于以下设计方案搭建,主要包括主要围绕 PC 与 ZYNQ、ARM 与 FPGA 这两组设备的通信展开,信号传输包括数据流和控制流。其中,PC 与 ZYNQ 之间的数据采用基于 UDP 协议的网口进行传输,而 ARM 与 ZYNQ 之间的数据采用片内的 AXI 总线和接口传输。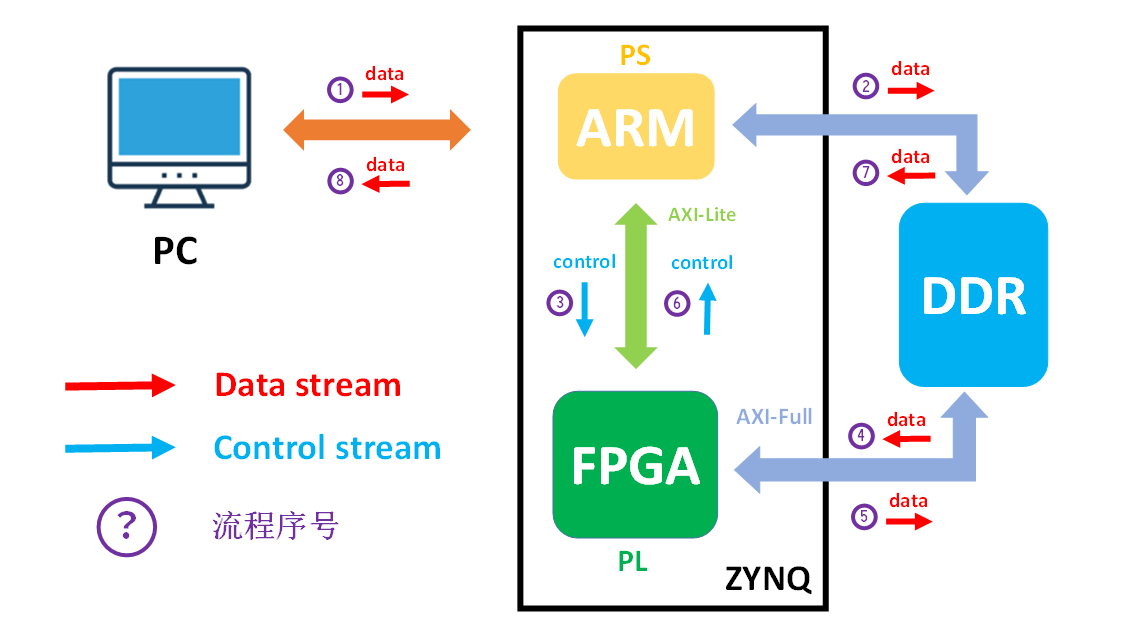
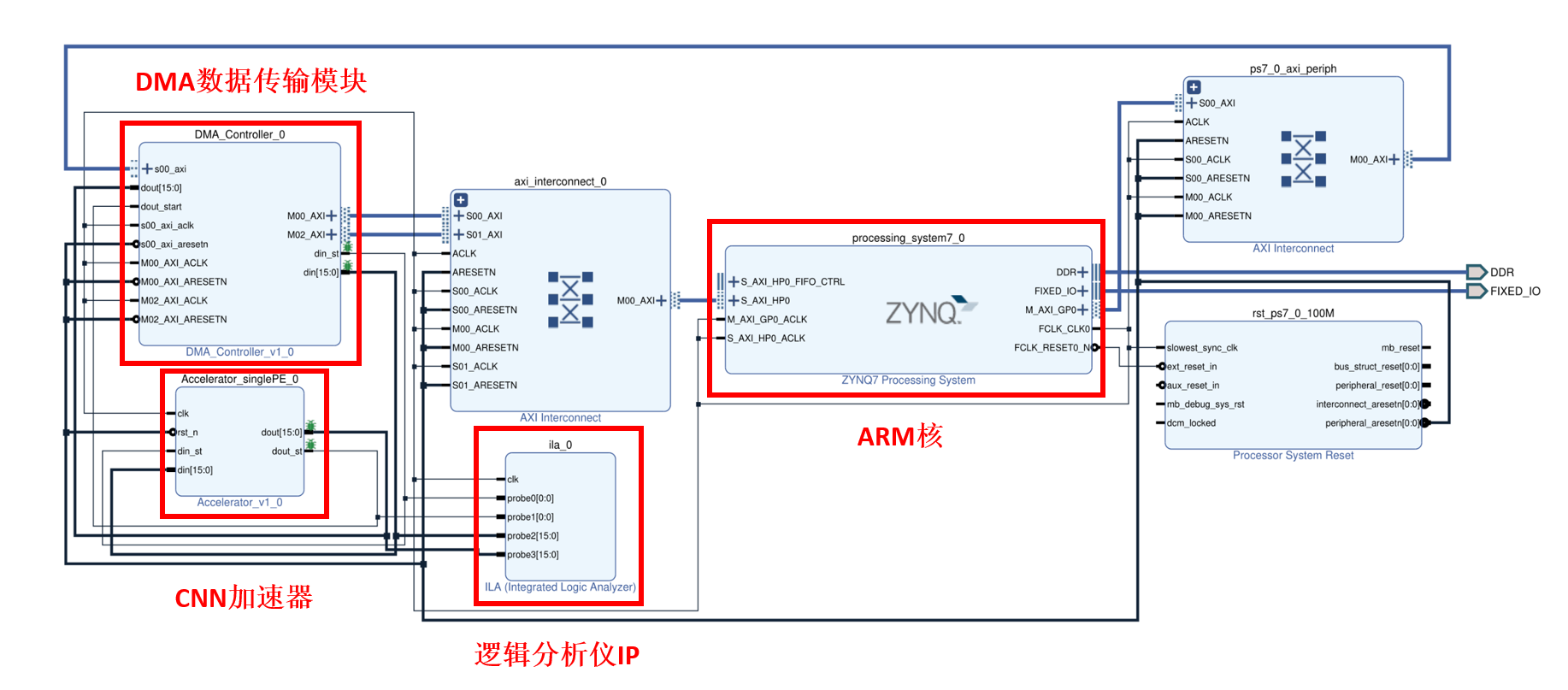
加速器的实验测试
功能测试
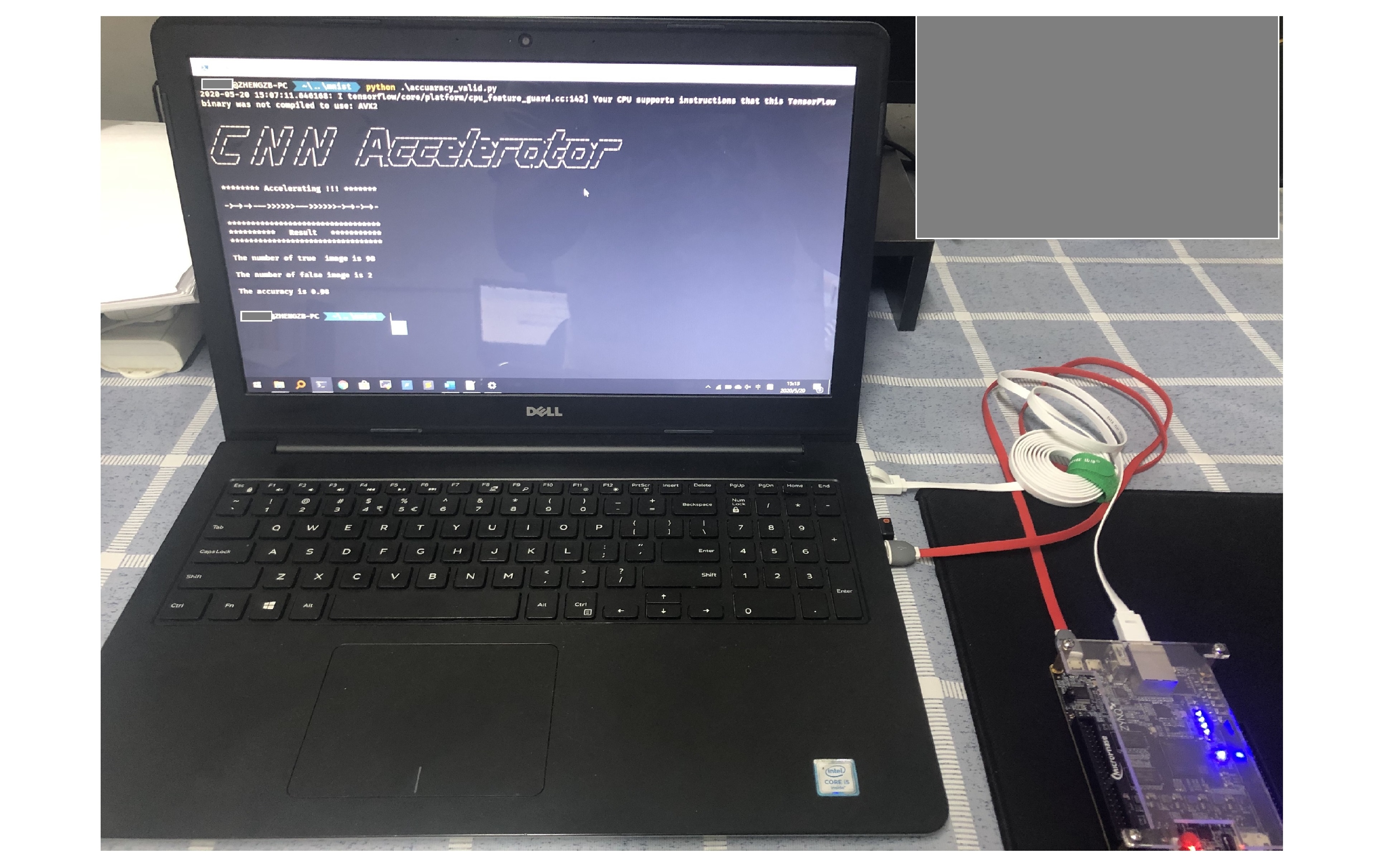
加速器的功能测试是基于图3搭建的软硬件协同工作平台,实验中使用 10000 张测试集图片进行测试,最终识别正确的图片为 9842 张,即测试集的识别准确率为 98.42%,而 Tensorflow 32 位浮点数计算的识别准确率为 98.47%,两者仅相差 0.05%。其 PC 终端显示的结果如图4所示: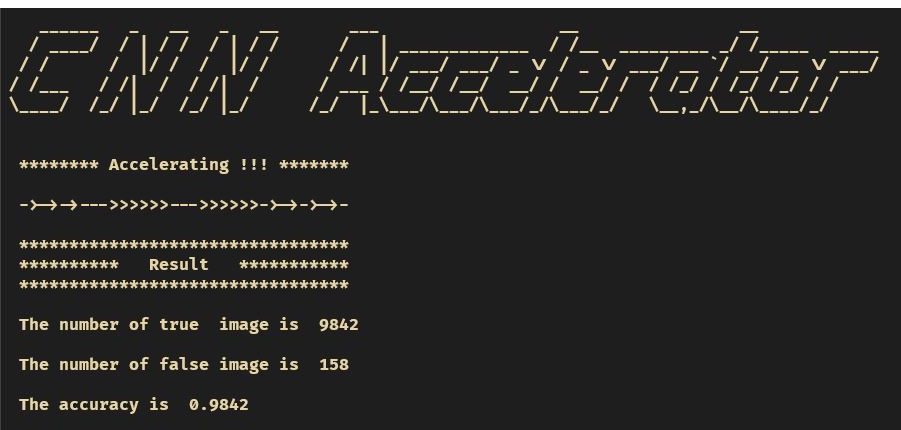
| Tensorflow准确率 | 加速器准确率 | 准确率误差 |
|---|---|---|
| 98.47% | 98.42% | 0.05% |
性能测试
实验测试内容包括单张图片计算时间测试和10000张图片计算时间测试,并与笔记本CPU(i5-6200U)计算时间进行了对比。最终计算性能对比如下:
| 测试案例 | CPU | CNN加速器 | 加速比 |
|---|---|---|---|
| 单张图片/${\mu}s$ | 3985 | 47 | 84.8 |
| 10000张图片/$ms$ | 21455 | 497 | 43.2 |
硬件资源消耗方面,该加速器的资源消耗情况如下表所示。其中 DSP 和LUT 资源消耗最多,DSP 资源利用率达到了 100%,这是因为在卷积计算单元中需要消耗较多的硬件乘法器,而加法树中的加法器硬件都是由LUT实现的。
| Resource | Utilization | Available | Utilization / % |
|---|---|---|---|
| LUT | 13619 | 17600 | 77.38 |
| LUTRAM | 678 | 6000 | 11.3 |
| FF | 12594 | 35200 | 35.78 |
| BRAM | 29 | 60 | 48.33 |
| DSP | 80 | 80 | 100 |
功耗方面,利用 Vivado 功耗估计器(XPE) 进行功耗的评估,最终得到加速器的总功耗为 1.991W。各部分的功耗分布如图5所示。其中,动态功耗包括时钟、信号、逻辑、片上存储、DSP 和 PS 端等资源消耗的功率,共计 1.863W,占整个加速器功耗的94%;静态功耗表示正常工作时晶体管漏电流消耗的功率,主要由芯片的设计本身决定,共计 0.129W,占整个加速器功耗的6%。加速器的功耗为总功耗减去PS侧的功耗,故实际加速器的功耗为0.458W。
