Going Deeper with Embedded FPGA Platform for Convolutional Neural Network
FPGA’16, February 21-23, 2016, Monterey, CA, USA
Abstract
- CNN 模型中卷积层是以计算为中心,而全连接层是以内存为中心,即限制卷积层计算速度的关键在于大量的数据计算,而全连接层相比数据计算而言,限制速度的瓶颈在于数据读取的带宽
- 采用动态数据量化方法和一种卷积核的设计实现在整个 CNN 模型,可以提高 带宽 和 资源的利用率
Platform
- Device: Xilinx Zynq ZC706
- CNN Model: VGG16-SVD
Key Content
一种动态数据的量化方法
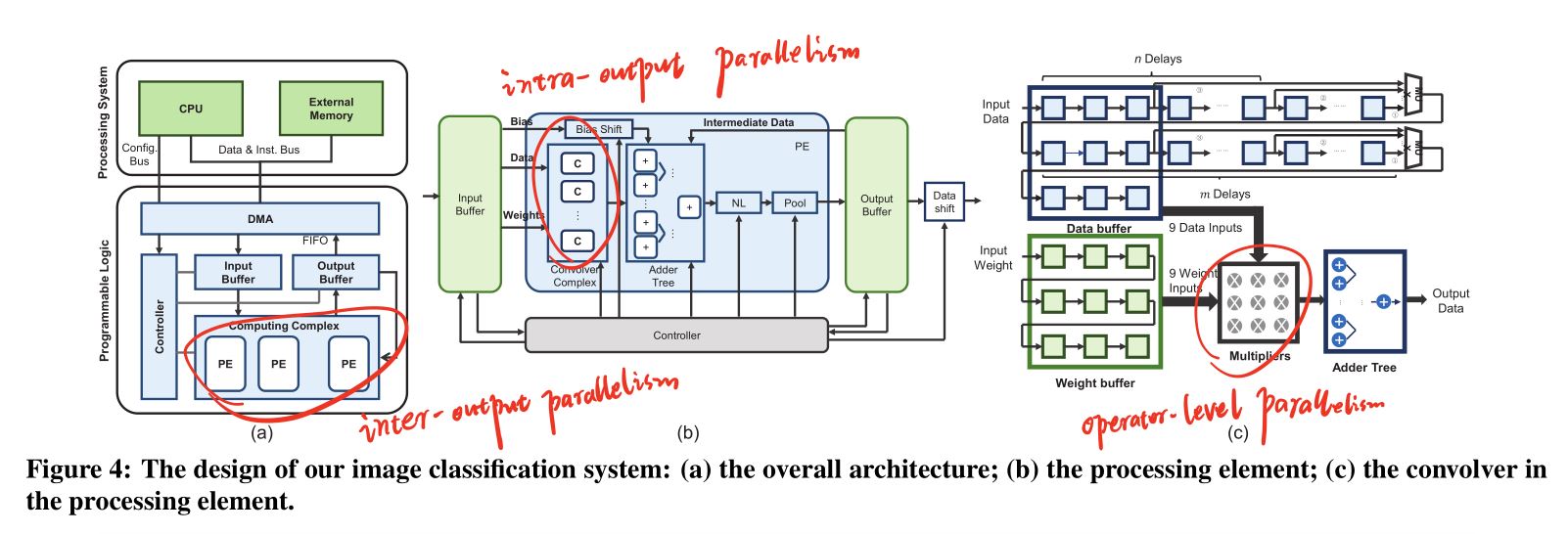
卷积核的3种并行
- 乘法器之间的并行
- 卷积核运算单元之间的并行
- 处理单元PE之间而的并行
数据搬移策略